应用评测
星辰应用平台聚合多方服务工具和组件,整体效果评测和优化是应用落地的关键因素,本模块主要结合应用的真实使用效果,输出应用效果评测的方式、方法、策略,全方位输出评测报告,实现端到端的效果评估,支持数据回流,自动分析评测日志,输出优化建议,支持微调模型,实现全链路效果持续优化闭环。
💡 构建完工作流后,您可以通过评测,有效地发现应用中的不足之处,并验证其实际效果。创建评测集
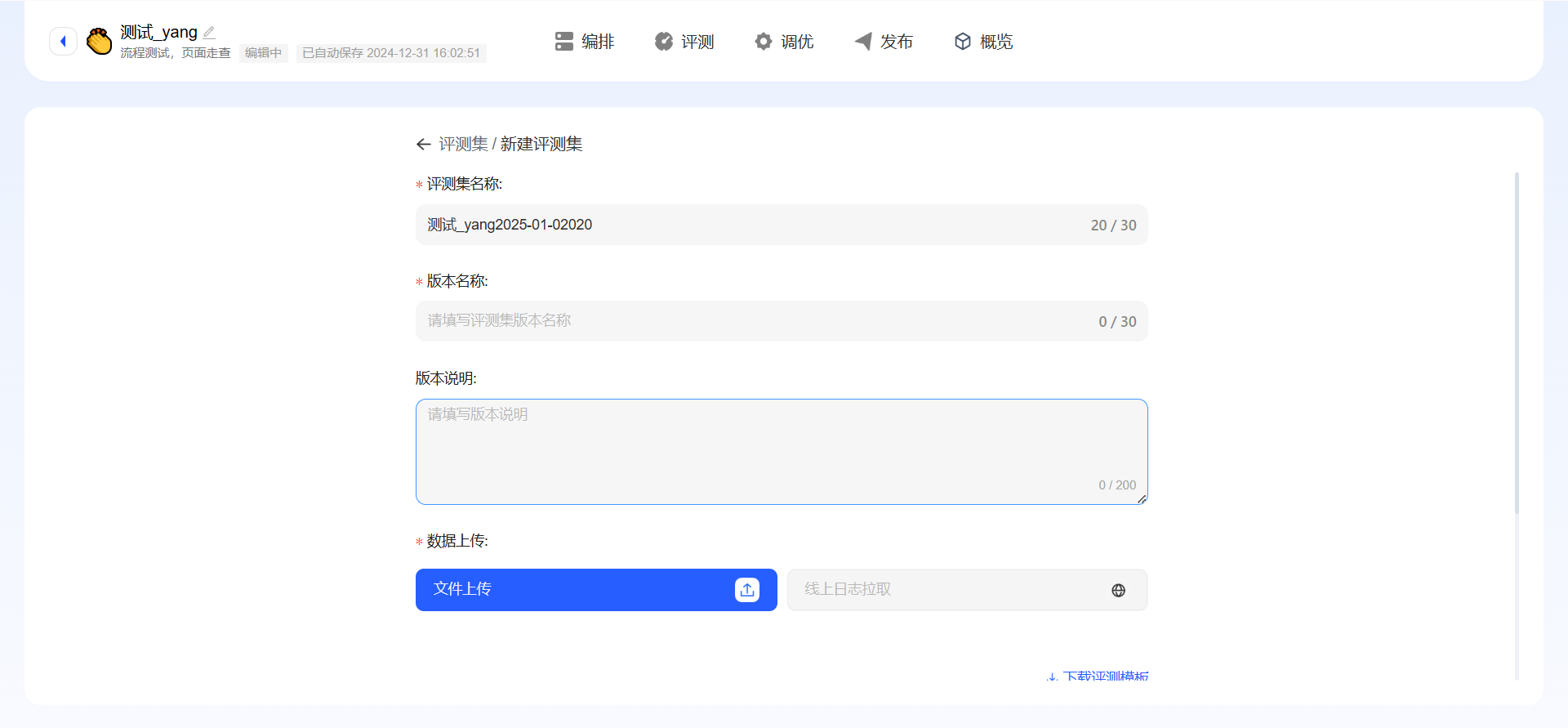
构建评测任务离不开充足的数据支持,因此在着手创建评测任务之前,需要先建立相应的评测数据集。
- 登录星辰大模型平台;
- 在编排并调试完成应用之后,头部导航栏中选择数据集,并在页面tab栏选择评测集;
- 点击新建评测集,默认当前应用名称+评测集作为评测集名称,进入该评测集版本创建页,填写基本信息,数据支持文件上传和线上日志拉取,数据上传支持下载评测模板,可根据模板进行填写数据,模板中输入下方字段必填,期望输出非必填;若已有评测集,支持新建版本,也支持在已有版本内添加、修改或删除数据;
- 单条数据新增:在评测集版本列表页点击新增,列表新增一行,填写完成即可;
- 批量新增:点击批量新增,支持线上日志拉取和上传文件两种方式,上传文件仅支持xlsx格式的文件,文件大小不能超过20MB;
创建评测任务
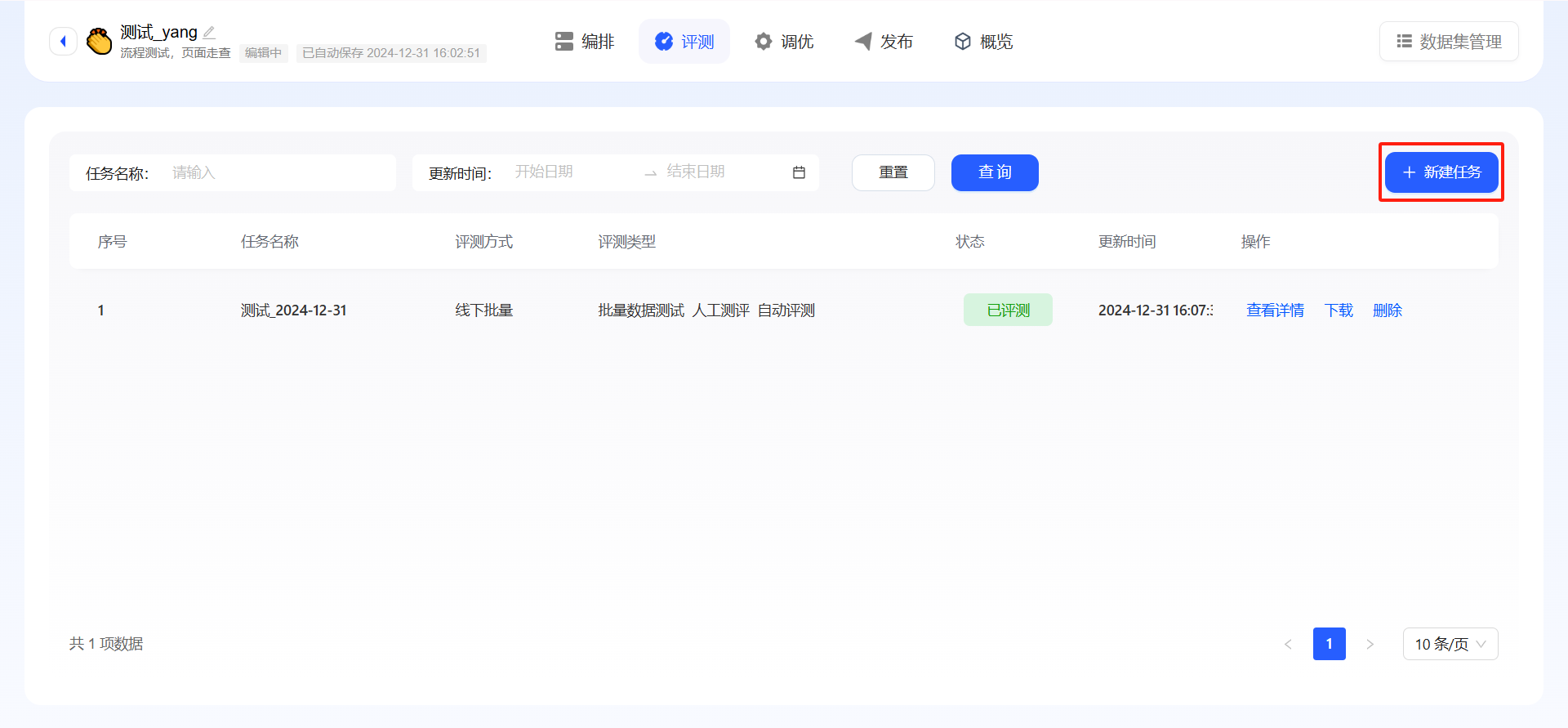
- 登录星辰大模型平台;
- 在编排并调试完成应用之后,头部导航栏中选择测评,跳转至测评列表页;
- 点击新建评测任务按钮,进入新建页面。
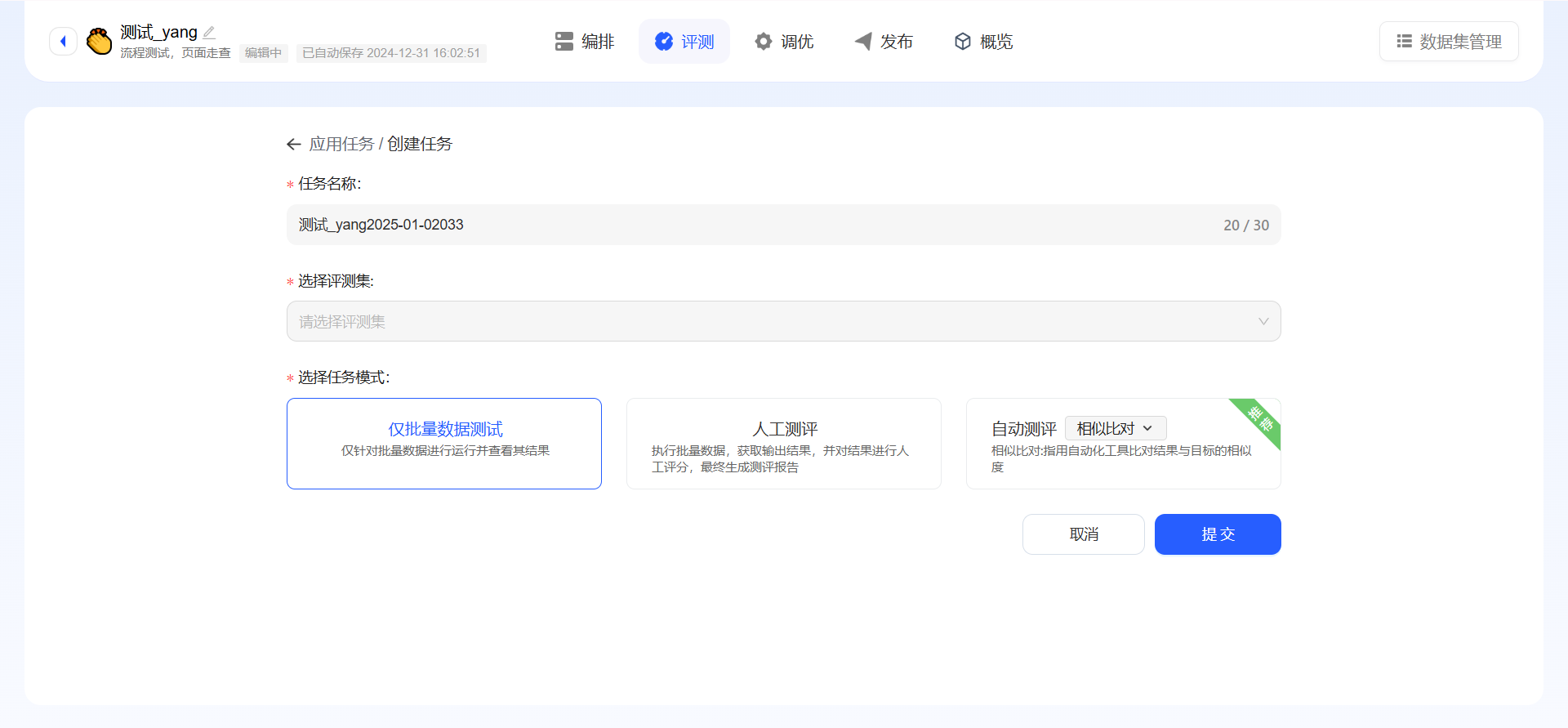
- 填写任务基本信息:任务名称、选择应用版本、选择数据集来源、选择评测集、选择任务模式,点击提交即可
- 选择应用版本:当应用已存在线上版本,且还存在线上草稿版本时,此项需做选择;
- 选择数据集来源:当应用已存在线上版本,此项需做选择;线下批量评测需提供评测集,如果没有评测集,可新增评测集;线上日志拉取无需自行提供;
- 选择评测集:如果是线下批量测评,可选择所有符合测试该应用的评测集;线上日志拉取,只需按照采样时段、采样总量、采样方式从线上直接拉取数据即可;
- 任务模式:仅批量数据测试(可选择没有期望输出的测试集)、人工测评(可选择没有期望输出的测试集)、自动测评(必须选择有期望输出的测试集数据,相似比对相似比对:指用自动化工具比对结果与目标的相似度,精确比对:精确比对:指用自动化工具比对结果与目标是否完全匹配),可多选;
评测报告
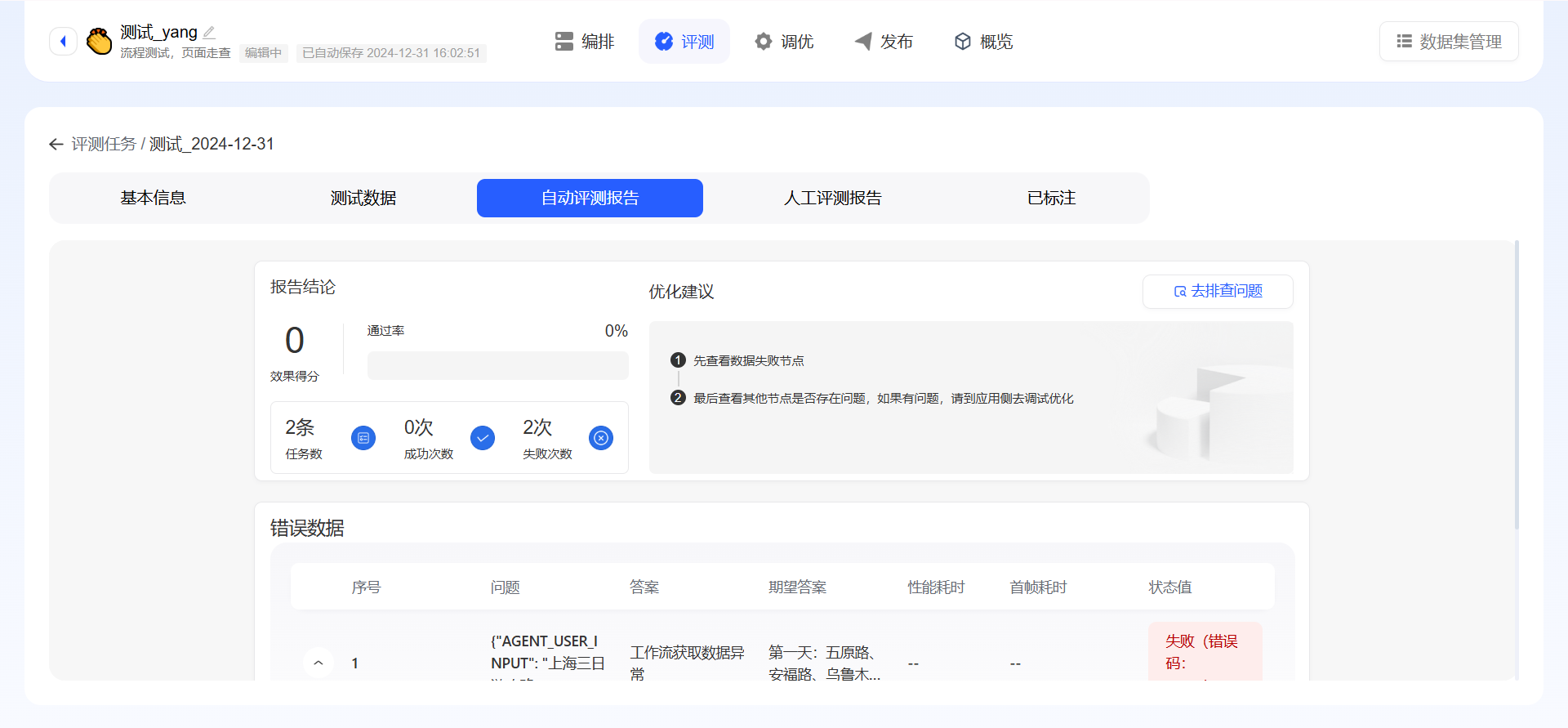
- 仅批量数据测试:任务详情页展示基本信息和测试数据,测试数据支持标注;
- 人工测评:需手动进行人工打分,提交后,则任务状态变为已评测,任务详情页展示基本信息、测试数据和人工测评报告,测试数据支持标注;
- 自动测评:提交后自动打分,任务详情页展示基本信息、测试数据和人工测评报告,测试数据支持标注;
- 报告详情:报告结论+优化建议,报告结论中会展示执行总数量、成功数量、失败数量、成功率、错误码占比、执行失败节点次数以及整体得分情况;优化思路可按照优化建议步骤一一排查,也可按照自已的思路快速进行排查;
- 可以对大模型、决策以及变量提取器这三类节点进行标注。这些节点均支持通过训练模型来优化其效果。用户可以创建优化任务,将已标注的数据提交用于训练,从而得到效果提升后的模型。
得分说明:【0-50)较差,【50-70)一般,【70-100】较好
评测指标及计算公式如下:
- 召回率 (Recall)
准确率 (Precision)
F1 值
公式说明:
GT:用户期望的问题答案
answer:用户选择的技能或助手生成相应的answer
GT要点集合:LLM 裁判从GT中抽取出的要点信息
answer要点集合:LLM 裁判从answer中抽取出的要点信息
召回率:召回率是用于评估推荐系统或分类系统完整性的一种指标。它衡量系统推荐或预测的相关项目占所有相关项目的比例。
高召回率: 高召回率值表明系统在捕捉大多数相关项目方面表现良好,即使其中包括一些不相关的项目。这意味着系统在推荐中非常彻底。
低召回率: 低召回率值表明系统遗漏了许多相关项目。这意味着系统可能过于保守,没有向用户推荐足够多的项目。
准确率:准确率是用于评估推荐系统或分类系统准确性的一种指标。它衡量系统推荐或预测的项目中有多是相关的。
高准确率: 高准确率值表明推荐的项目中有很大比例是相关的。这意味着系统在选择相关项目方面表现良好,但可能为了保持高准确率而不推荐太多项目。
低准确率: 低准确率值表明推荐的项目中有很多不相关的项目。这意味着系统可能推荐了太多项目,包括许多不相关的项目。
F1 值:F1评分是用于评估推荐系统或分类系统中准确率和召回率平衡的一种指标。它是准确率和召回率的调和平均只数,提供了一个同时考虑两者的单一分数。
高F1评分: 高F1评分值表明准确率和召回率之间有良好的平衡,这意味着系统在推荐中既准确又全面。
低F1评分: 低F1评分值表明准确率和召回率之间存在不平衡,这意味着系统可能遗漏了许多相关项目(低召回率)或推荐了太多不相关项目(低准确率)。