能力版本创建
准备工作
创建版本前,需要您提前做如下准备:
步骤一:准备内容确认&基本信息填写
登录引擎托管平台(以下简称ASE)控制台,并选择一个AI能力,进入版本管理页;
点击“新建版本”,进入版本创建页;
当该AI能力未被发布过时,每次进入版本创建页时,需对创建版本所需的内容进行已完成确认,以确保创建版本时,可以流畅完成;
针对已完成的内容进行勾选,未完成的内容请根据后方提示完成,其中模型上传为非必选项。所有准备工作已确认完成后,点击“开始创建”进入第一步:基本信息填写;
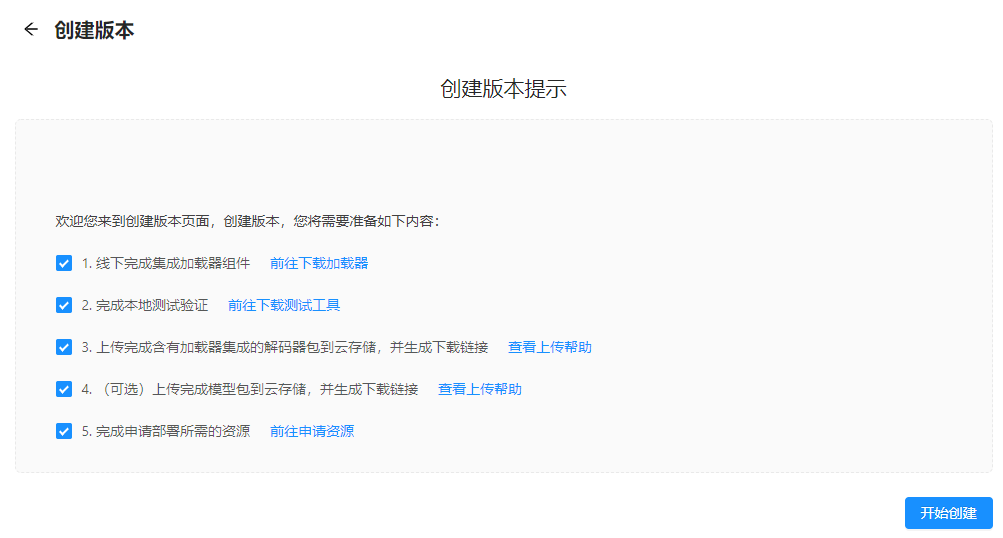
根据实际情况,按需填写版本信息。其中,能力版本号需按照国际通用版本管理标准:版本格式:主版本号.次版本号.修订号。当AI能力已上架时,如存在不兼容更新时,则需另外创建一个AI能力;
版本号递增规则如下:
主版本号:有不兼容的更新时
次版本号:有向下兼容的功能性新增
修订号:有向下兼容的问题修正
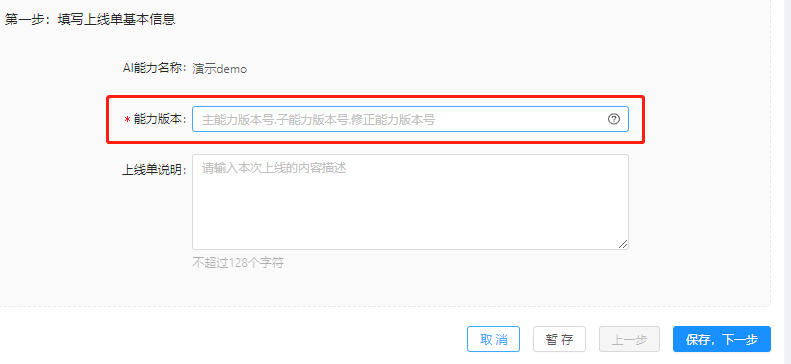
步骤二:接口定义
接口定义共需定义5个内容,详细说明如下:
- 接口协议基本信息:
| 字段 | 解释说明 |
|---|---|
| Service_ID | AI能力的唯一标识 |
| 状态 | 当AI能力处于未发布、已发布状态时,允许开发者对接口协议进行新增、修改、删除等操作,不对接口兼容性做强制管理; 当AI能力处于已上架状态时,为保障引擎使用者的正常使用,仅允许开发者对接口协议进行新增; |
| 当前版本 | 接口协议的版本标识,用以描述当前协议所处的版本状态 |
| 服务别名 | AI能力的自定义代称,默认为Service_ID。用于接口协议中对AI能力的表述,在后续的请求数据段、响应数据段中均会自动带入服务别名的信息,推荐AI能力的实际功能进行重命名。支持英文、数字、下划线组合,不超过16个字符 |
| 接口类型 | 支持创建非流式接口(接口协议为:HTTP1.1),或流式接口(接口协议为:WebSocket)。 流式接口即建立长连接模式,支持用户建立连接后可持续发送请求数据,引擎进行计算后持续输出。 非流式接口即建立连接后,一次性输入请求数据,一次性出结果 |
- 功能定义:
功能定义用以描述控制功能调用时的参数名称,AI能力使用者可通过传参数及其取值,从而调用引擎提供的功能,点击“添加自定义参数”,在自定义参数浮框中填写对应内容。
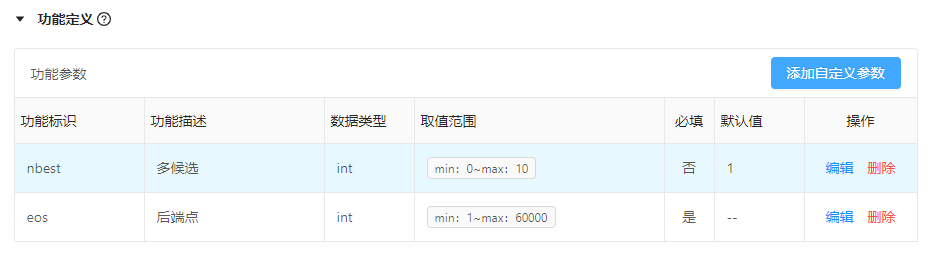
| 字段 | 解释说明 |
|---|---|
| 功能描述 | 功能含义的简要描述,支持汉字、英文、数字组合,不超过128字符 |
| 功能标识 | 功能的参数定义,支持英文、下划线、数字组合,不超过32字符 |
| 数据类型 | 功能取值的数据类型,根据功能含义进行选择,包含整数型、浮点型、枚举型、布尔型、字符串、时间型 |
| 约束类型 | 功能取值的约束类型,包含范围取值、枚举。其中范围取值表示该功能取值的上下限,而枚举中的每一个取值,均需说明各取值的含义 |
| 是否必填 | 标识该功能在AI能力使用者进行调用时,是否必传。通常情况下,影响引擎的基础功能为必填项,进阶型功能为非必填项 |
| 默认值 | 非必填,如果该功能为非必填项,需明确该功能的默认取值 |
- 请求数据定义:
请求数据描述该AI能力的请求数据个数及各请求数据的类型,如【语音合成】的请求数据仅1个,请求数据类型为文本类型,【语音转写】的请求数据个数为1个,请求数据类型为音频类型,ASE提炼出业界通用的标准请求数据类型以供开发者选择。基于不同的接口类型,请求数据的内容及取值范围有一定差别。
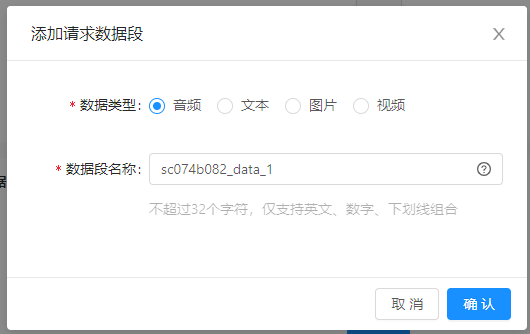
| 字段 | 解释说明 |
|---|---|
| 数据类型 | 用以描述请求数据的数据类型,包含音频、文本、图片、视频 |
| 数据段名称 | 用于接口协议中对该数据段的标识,推荐根据数据段类型及含义进行命名。不超过32个字符,仅支持英文、数字、下划线组合 |
生成的请求数据: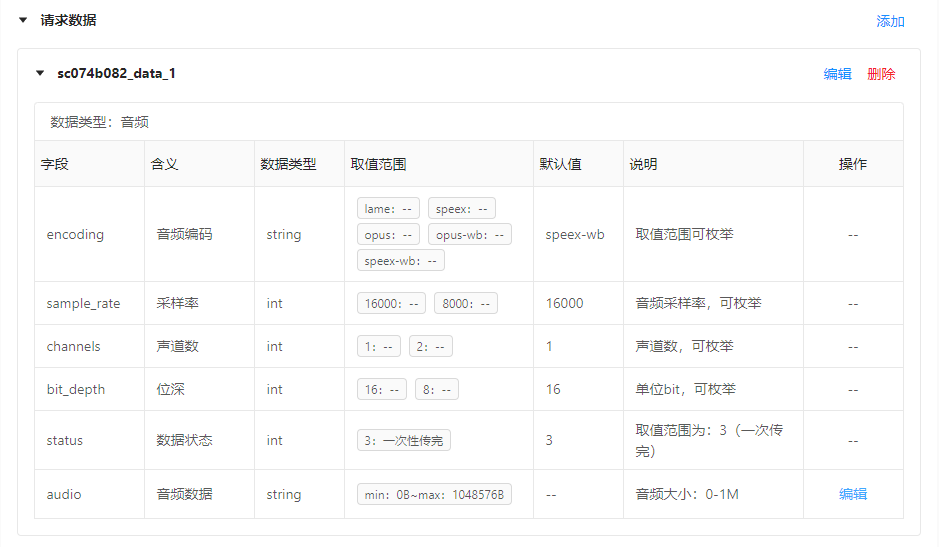
- 响应数据定义:
请求数据描述该AI能力的请求数据个数及各请求数据的类型,如【语音转写】的响应数据仅1个,响应数据类型为文本类型,ASE提炼出业界通用的标准请求数据类型以供开发者选择。基于不同的接口类型,响应数据的内容及取值范围有一定差别。
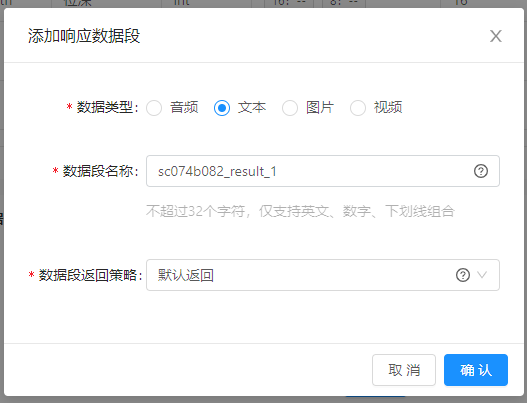
| 字段 | 解释说明 |
|---|---|
| 数据类型 | 用以描述响应数据的数据类型,包含音频、文本、图片、视频 |
| 数据段名称 | 用于接口协议中对该数据段的标识,推荐根据数据段类型及含义进行命名。不超过32个字符,仅支持英文、数字、下划线组合 |
| 用户描述不同策略下响应结果内容,策略包括默认返回、符合条件时返回,其中符合条件时返回根据定义功能参数自定义响应结果内容和格式 |
生成的响应数据:
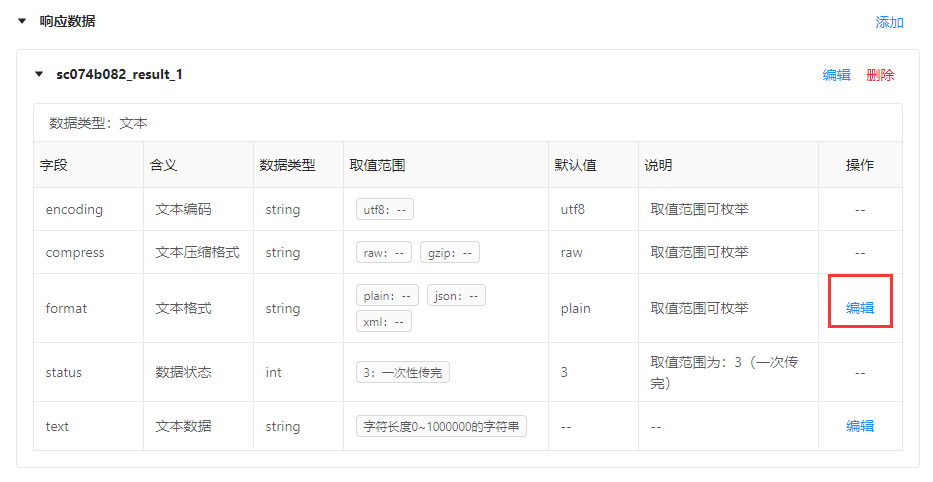
若响应结果为json时,需编辑format,给出json样例以及字段说明
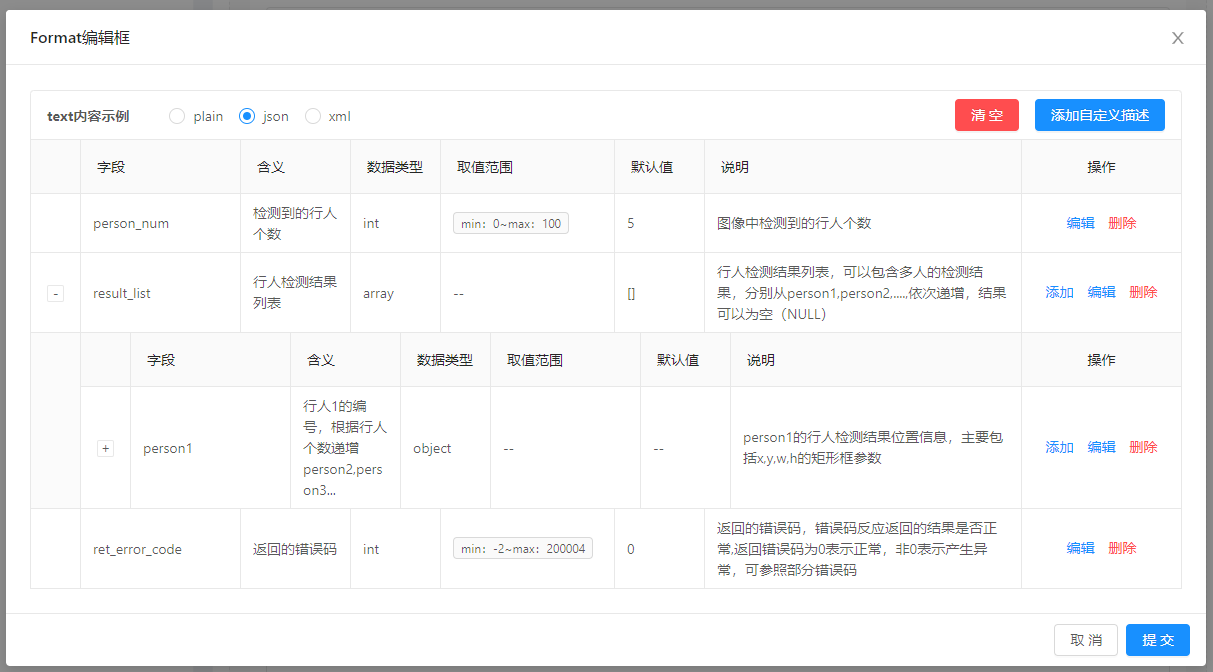
- 错误码定义:
错误码定义即调用AI能力失败时,引擎侧返回的错误代码,以帮助用户进行错误区分并根据提供的处理策略进行修正。点击“添加错误码”,在弹框中填写对应信息,即可新增错误码。
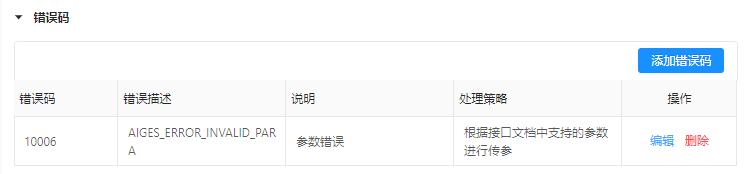
| 字段 | 解释说明 |
|---|---|
| 错误码 | 开发者自定义的引擎错误编码,业界通常为5~7位,错误码与系统本身错误码已隔离,请放心填写 |
| 错误描述 | 对当前错误状态的客观表述,支持英文、数字、下划线、横杠组合;上限256字符。如:AIGES_ERROR_INVALID_PARA |
| 说明 | 对错误码产生的原因进行详细描述,支持中文、英文、数字、下划线、横杠组合;上限518字符 |
| 处理策略 | 对该错误类型的建议处理策略,支持中文、英文、数字、下划线、横杠组合;上限518字符 |
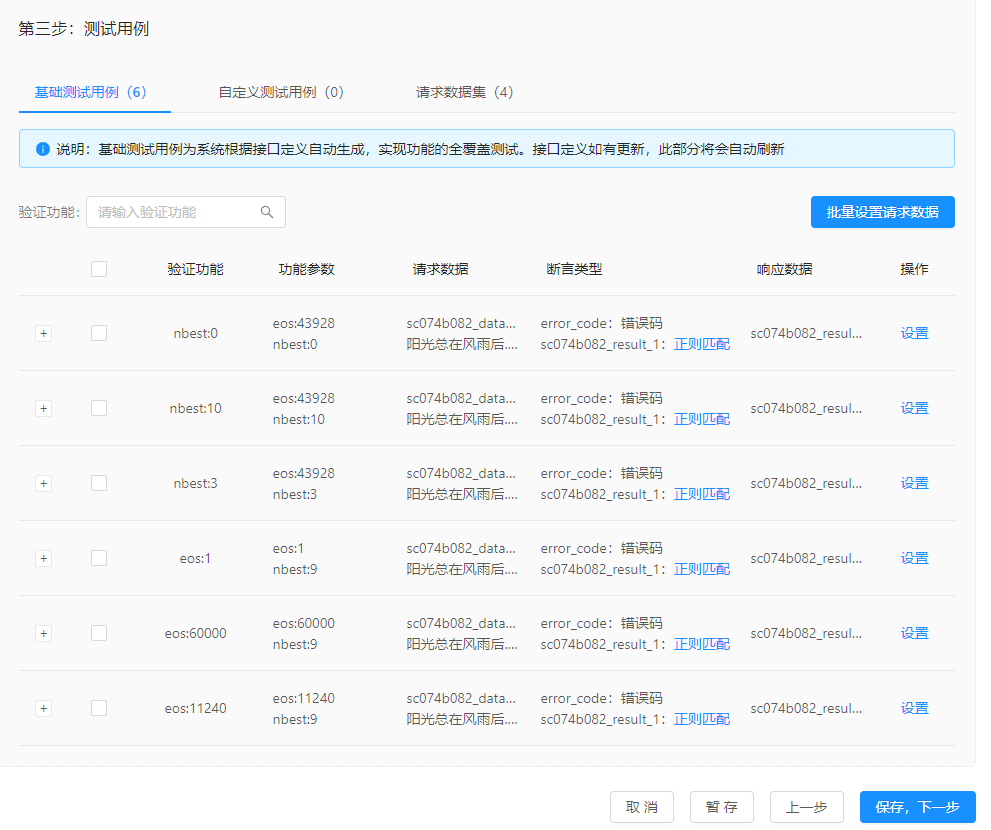
步骤三:测试用例
填写完接口协议后,基于接口协议中填写的功能参数,平台会自动生成基础测试用例,您也可以添加自定义测试用例
步骤四:资源上传
开发者需先完成解码器开发,并通过本地S3工具上传解码器及模型(可选)。
解码器为加载器、深度学习算法计算模块及连接加载器与计算模块的中间件的集合,解码器编写详见: 解码器编写
上传说明详见:解码器&模型上传
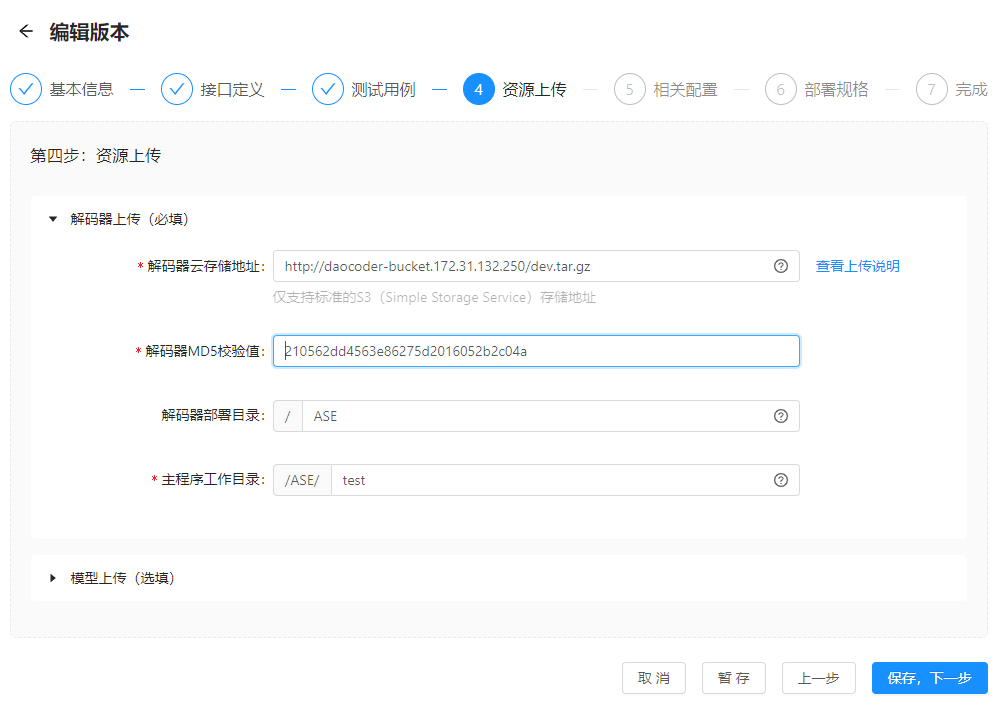
解码器上传字段说明:
| 字段 | 解释说明 |
|---|---|
| 解码器云存储地址 | 当前仅支持标准的S3存储地址,您需提前使用S3本地上传工具将解码器包,当前仅支持tar.gz格式,进行上传,并在此处粘贴生成的S3地址 |
| 解码器MD5校验值 | 文件的数字指纹,判断文件传输中是否有损的一种校验方式 |
| 解码器部署目录 | 期望的解码器部署目录,系统将自行为您创建目录中包含的文件夹。默认将文件放置在/ASE中,用户可根据实际情况重新填写 |
| 主程序工作目录 | 解码器包中,主程序的运行目录,ASE部署平台将凭借您填写的目录在解压后的文件夹中查找并启动 |
模型上传说明:
注:如引擎中未使用到模型,则此项可不填。
| 字段 | 解释说明 |
|---|---|
| 模型云存储地址 | 当前仅支持标准的S3存储地址,您需提前使用S3本地上传工具将解码器包,当前仅支持tar.gz格式,进行上传,并在此处粘贴生成的S3地址 |
| 模型MD5校验值 | 文件的数字指纹,判断文件传输中是否有损的一种校验方式 |
| 模型部署目录 | 期望的模型部署目录,需与解码器中实际编写的计算模块中填写的模型目录保持一致 |
步骤五:相关配置
相关配置用来描述引擎部署的环境及引擎支持的并发情况
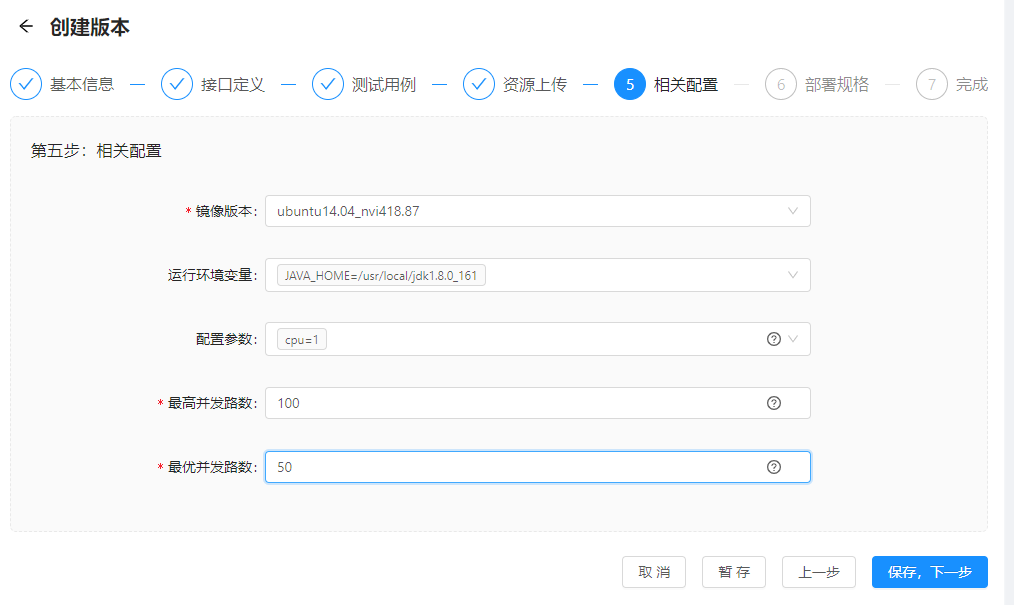
| 字段 | 解释说明 |
|---|---|
| 镜像版本 | 运行软件环境:包含OS,驱动,基础库。共提供两类镜像: ubuntu:14.04_niv18.87: 操作系统:ubuntu14.04 GPU驱动:418.87.00 CUDA版本:10.1 |
| 运行环境变量 | 系统运行时的环境变量 |
| 配置参数 | 加载器插件的初始化接口中定义的配置对 |
| 最高并发路数 | 表示单节点支持的最大并发路数,超过该并发时,用户请求服务失败 |
| 最优并发路数 | 单节点支持的最佳并发路数,小于等于该并发路数时,用户请求服务时性能最优 |
步骤六:部署规格
不同的AI算法引擎需要不同的计算资源,通常情况下,计算量越大的引擎,所需的资源规格越高。ASE当前提供8种资源规格,包含4种CPU资源、4种GPU资源。在选择部署规格时,需提前申请资源。申请说明详见:服务器资源申请
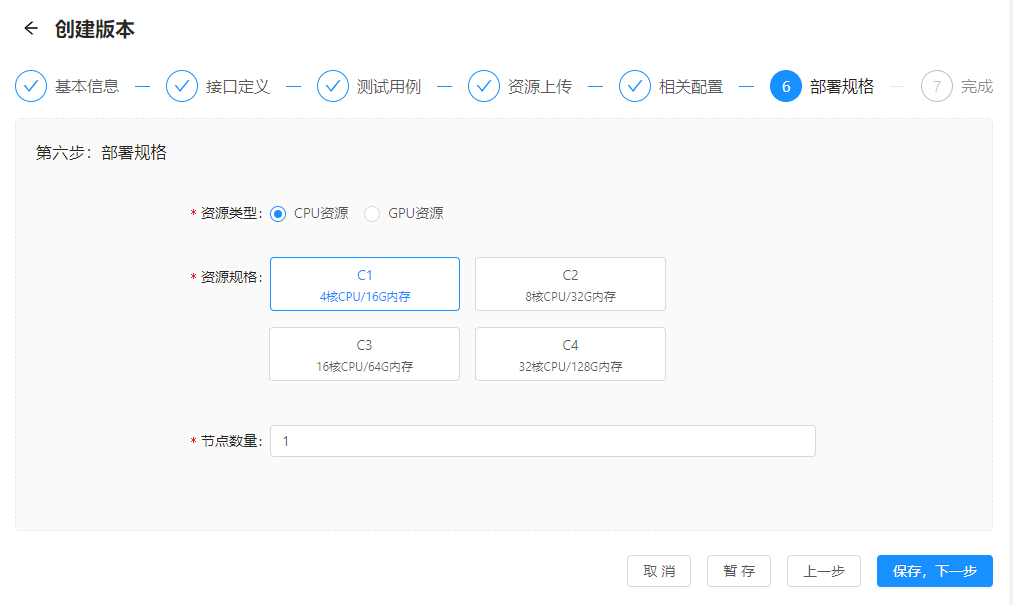
| 资源类型 | 资源规格 |
|---|---|
| CPU资源 | C1:4核CPU/16G内存 C2:8核CPU/32G内存 C3:16核CPU/64G内存 C4:32核CPU/128G内存 |
| GPU资源 | G1:CUDA版本10.1/GPU显存2G/4核CPU/16G内存 G2:CUDA版本10.1/GPU显存4G/8核CPU/32G内存 G3:CUDA版本10.1/GPU显存8G/16核CPU/64G内存 G4:CUDA版本10.1/GPU显存12G/32核CPU/128G内存 |
步骤七:完成创建版本
版本创建完成后,可选择直接进行版本验证,或前往版本详情页。
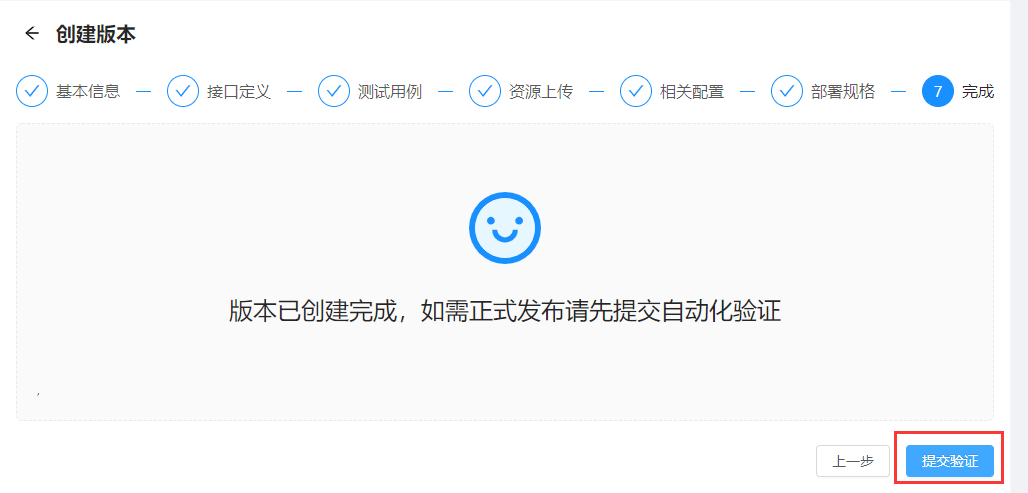
版本提交验证后,将会拉取用户提交的解码器及模型,在测试环境进行部署,并使用开发者编写的测试用例进行在线验证。验证时间将受解码器及模型大小、测试用例条数影响。
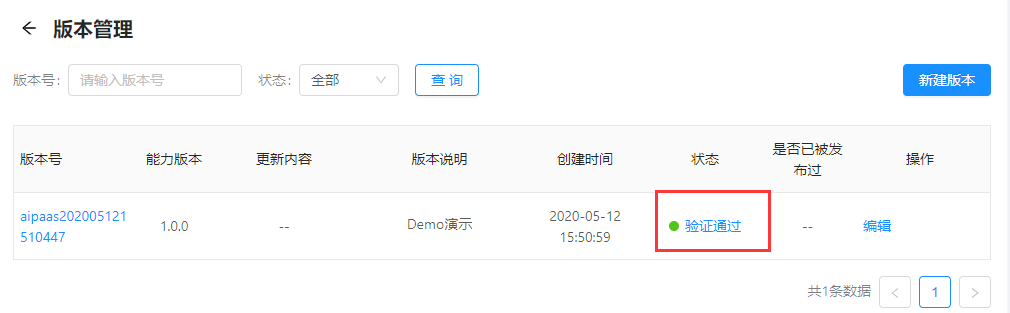
能力版本验证通过后,可对该AI能力进行发布上架等操作。
下一步:能力发布&上架